| Webcrow 1.0: Implementation Details |
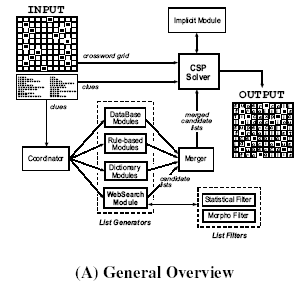
| We designed WebCrow's architecture (figure below) using some insights from Proverb's. The information flow is similar: in a first phase the clues are analyzed by a set of candidate-list generators (the expert modules). Among these the preliminary role is played by the Web Search Module (WSM). Each list contains a global confidence score and a set of words ordered by probability. These candidate lists are passed to a merger system that produces a unique list for each clue. In a second phase, a constraint-satisfaction algorithm carries forward the grid-filling, in order to place the correct words within the slots. |
|
| The Web Search Module represents the heart of WebCrow and the main innovation with respect to the literature. The goal of this important module recalls that of a Web-based Question Answering system. The idea is to exploit the Web and search engines (SE) in order to find sensible answers to questions expressed in natural language. However, with crossword clues, the nature of the problem changes sensibly, often becoming more challenging than classic QA. The only evident advantage in crossword solving is that we priorly know the exact length of the words that we are seeking. We believe that, thanks to this property, web search can be extremely effective. |
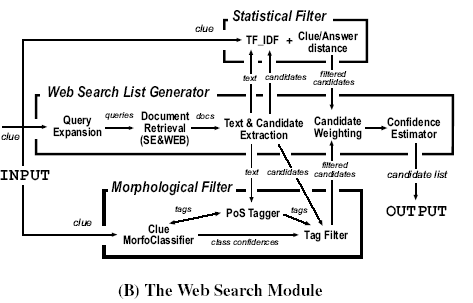 |
The inner architecture of the WSM is sketched in the figure above. It is based on three main sub-modules: a web-based list generator that extracts possible answers to a clue from web documents by picking the terms (and compound words) of the correct length, a statistical filter that ranks the candidates using statistical information retrieval techniques and a morphological filter that ranks the words according to their morphological category. WebCrow has been implemented mainly in Java with some parts in C++ and
Perl. The system has been compiled and tested using Linux on a Pentium
IV 2GHz with 2GB ram. |
| Some Results |
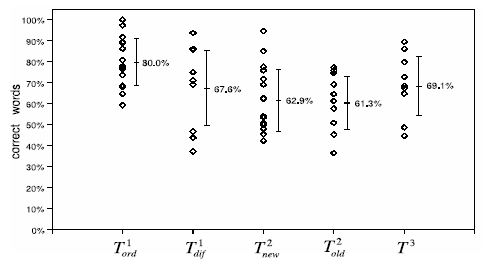
We partitioned the experimental set in five subsets. The first two belong to La Settimana Enigmistica, S1 ord containing examples of ordinary difficulty (mainly taken from the cover pages of the magazine) and S1 dif composed by crosswords especially designed for skilled cruciverbalists. An other couple of subsets belong to La Repubblica, S2 new and S2 old respectively containing crosswords that were published in 2004 and in 2001-2003. Finally, S3 is a miscellaneous of examples from crossword-specialized web sites. Sixty crosswords (3685 clues, avg. 61.4 each) were randomly extracted from these subsets in order to form the experimental test suite: T1 ord (15 examples), T1 dif (10 exs.), T2 new (15 exs.), T2 old (10 exs.) and T3 (10 exs.). To securely maintain WebCrow within the 15 minutes time limit we decided to gather a maximum of 30 documents per clue. ln less than 9 minutes we were able to download the documents, parse them and compute the statistical and morphological filtering. The other modules are much faster and the global list generation phase can be terminated in less than 10 minutes. To full the competition requirements we limited the grid-filling execution time to 5 minutes. If a complete solution is not found within this time limit the best partial assignment is returned. |
|
| The figure above shows WebCrow's performance on each example. On T1 ord the results were quite impressive: the average number of targets in rst position was just above 40% and the CSP module raised this to 80.0%, with 90.1% correct letters. In one occasion WebCrow perfectly completed the grid. With T1 dif WebCrow was able to ll correctly 67.6% of the slots and 81.2% of the letters (98.6% in one case) which is more or less the result of a beginner human player. On T2 new WebCrow performs with less accuracy averaging 62:9% (72% letters). On T2 old (old crosswords), due to the constant refreshing of Web's information, the average number of correct words goes down to 61.3% (72.9% letters). In the last subset the solving module is able to reach 69.1% words correct and 82.1% letters correct. Altogether, WebCrow's performance over the test set is of 68.8% (ranging from 36.5% to 100%) correct words and 79.9% (ranging from 48.7% to 100%) correct letters. |
 |
| The WSM (Web Search Module),
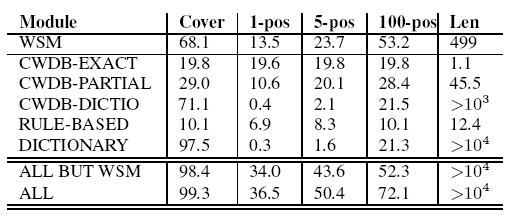
the heart of WebCrow's architecture, is able to produce impressive answering performances. It is in fact the module that provides the best coverage/precision balance, as it can be observed in the next table (first two columns). In over half of cases the correct answer can be found within the first 100 candidates within a list containing more than 10^5 words. The contribution of the WSM can be appreciated in the last two rows of the table where we observe the loss of performance of the whole system when the WSM is removed. The overall coverage of the system is mainly guaranteed by the Dictionary module, but the introduction of the WSM is fundamental to increase sensibly the rank of the correct answer. |
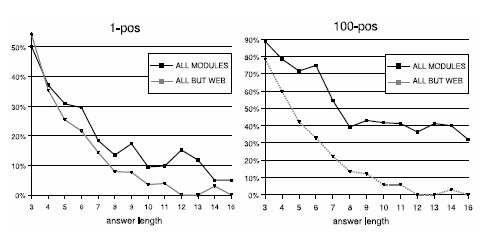 |
| This graph reports another very interesting result. Here we take into account the length of the target. It can easily be observed that the WSM guarantees very good performance even with long word targets, which are of great importance in the CSP phase. |